Table of Contents
Synthetic Mixed Training: Scaling Parametric Knowledge Acquisition Beyond RAG March 2026
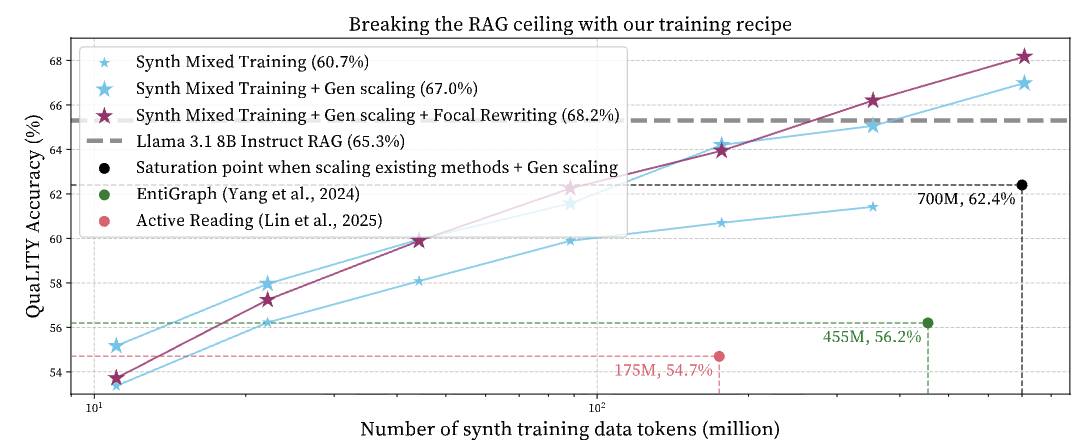
Mixing synth docs and QA has generator scaling and breaks RAG.
Synthetic data augmentation helps language models learn new knowledge in data-constrained domains. However, naively scaling existing synthetic data methods by training on more synthetic tokens or using stronger generators yields diminishing returns below the performance of RAG. To break the RAG ceiling, we introduce Synthetic Mixed Training, which combines synthetic QAs and synthetic documents. This leverages their complementary training signals, and enables log-linear improvements as both synthetic data volume and generator strength increase. This allows the model to outperform RAG by a 2.6% relative gain on QuaLITY, a long-document reading comprehension benchmark. In addition, we introduce Focal Rewriting, a simple technique for synthetic document generation that explicitly conditions document generation on specific questions, improving the diversity of synthetic documents and yielding a steeper log-linear scaling curve. On QuaLITY, our final recipe trains a Llama 8B model that outperforms RAG by 4.4% relatively. Across models and benchmarks (QuaLITY, LongHealth, FinanceBench), our training enables models to beat RAG in five of six settings, outperforms by 2.6%, and achieves a 9.1% gain when combined with RAG.
Links: Paper
Data-efficient pre-training by scaling synthetic megadocs March 2026
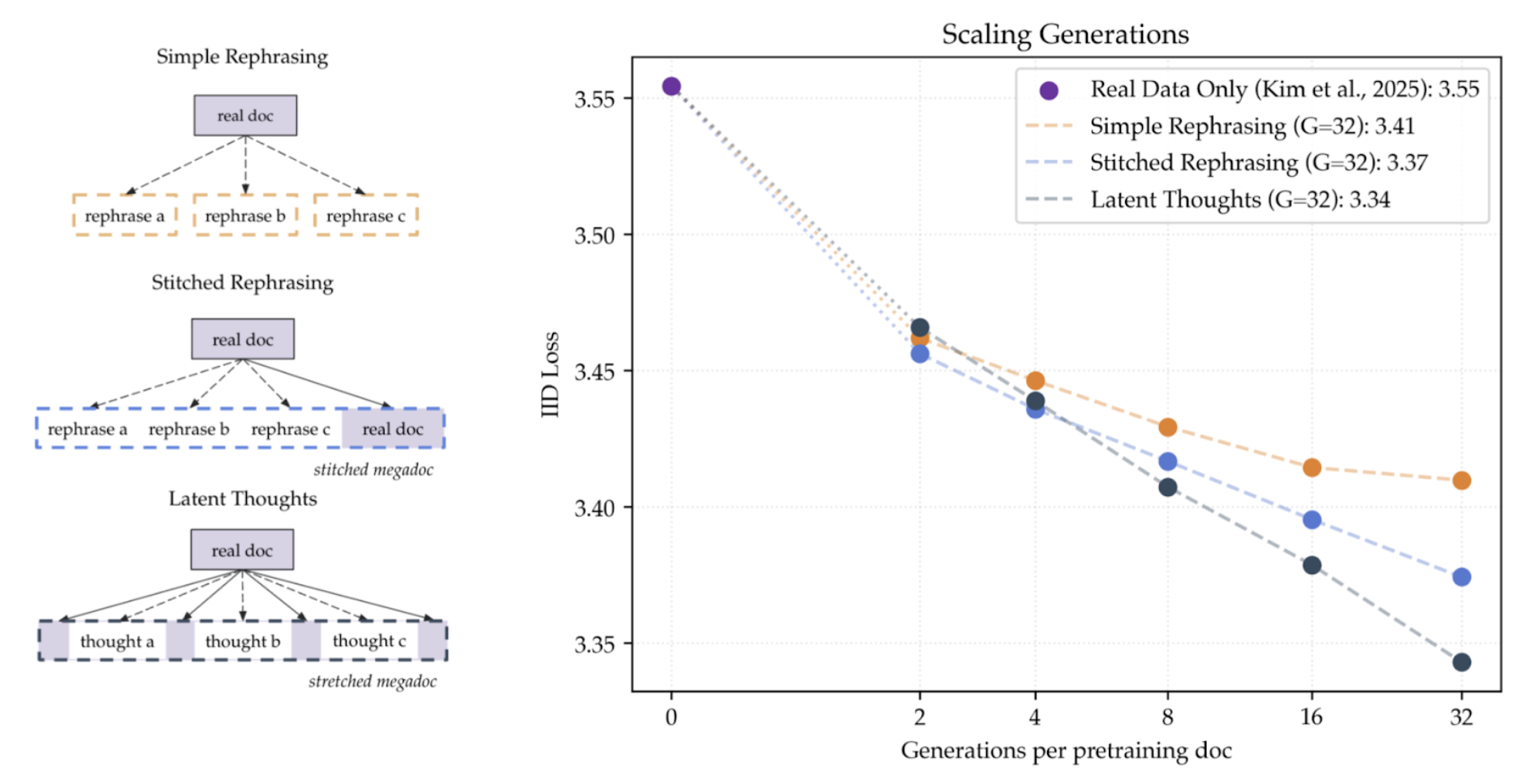
For data-efficient pre-training, treat synth generations from the same doc as a megadoc.
Synthetic data augmentation has emerged as a promising solution when pre-training is constrained by data rather than compute. We study how to design synthetic data algorithms that achieve better loss scaling: not only lowering loss at finite compute but especially as compute approaches infinity. We first show that pre-training on web data mixed with synthetically generated rephrases improves i.i.d. validation loss on the web data, despite the synthetic data coming from an entirely different distribution. With optimal mixing and epoching, loss and benchmark accuracy improve without overfitting as the number of synthetic generations grows, plateauing near 1.48x data efficiency at 32 rephrases per document. We find even better loss scaling under a new perspective: synthetic generations from the same document can form a single substantially longer megadocument instead of many short documents. We show two ways to construct megadocs: stitching synthetic rephrases from the same web document or stretching a document by inserting rationales. Both methods improve i.i.d. loss, downstream benchmarks, and especially long-context loss relative to simple rephrasing, increasing data efficiency from 1.48x to 1.80x at 32 generations per document. Importantly, the improvement of megadocs over simple rephrasing widens as more synthetic data is generated. Our results show how to design synthetic data algorithms that benefit more from increasing compute when data-constrained.
Pre-training under infinite compute September 2025
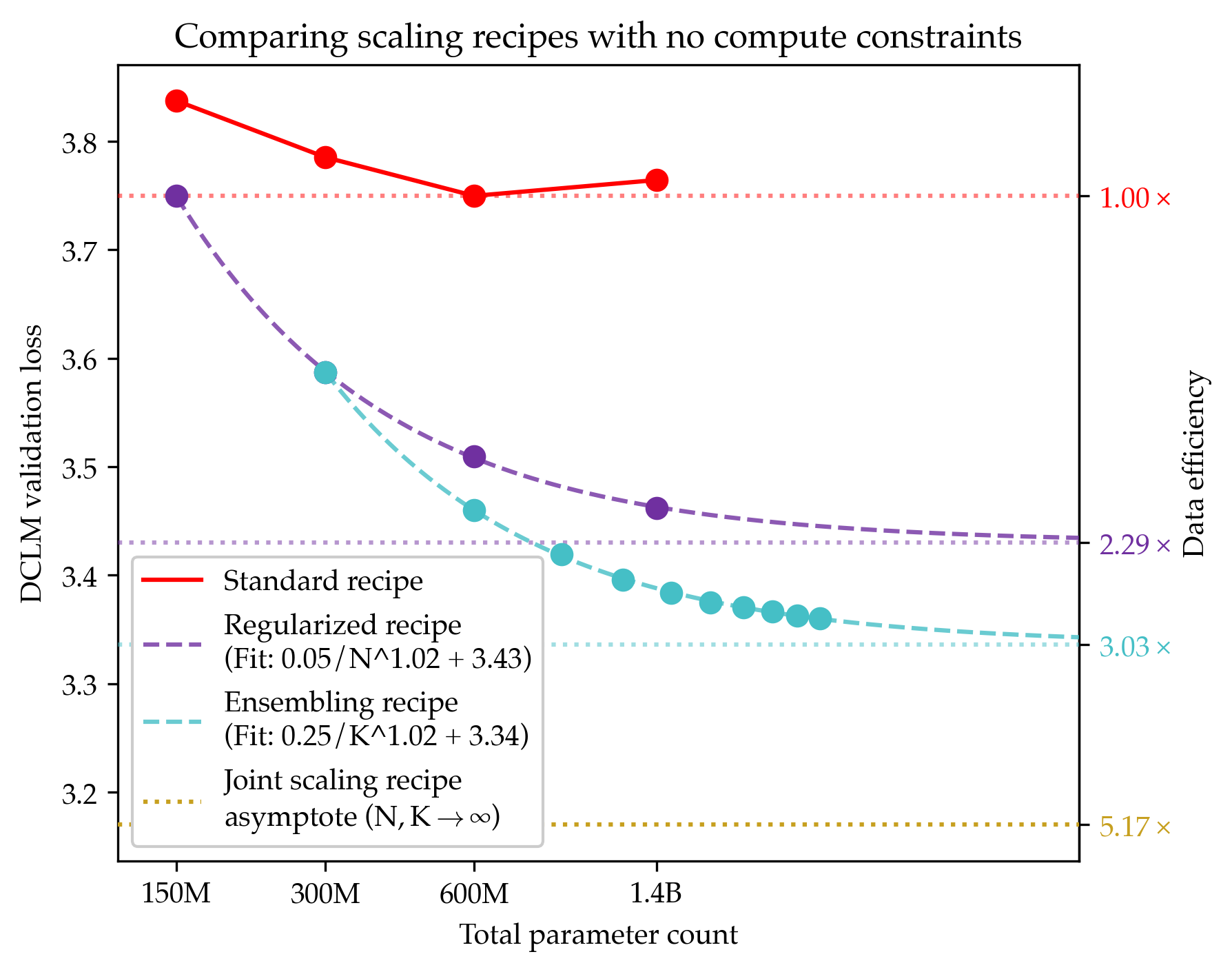
Data-efficient pre-training should better leverage infinite compute.
Since compute grows much faster than web text available for language model pre-training, we ask how one should approach pre-training under fixed data and no compute constraints. We first show that existing data-constrained approaches of increasing epoch count and parameter count eventually overfit, and we significantly improve upon such recipes by properly tuning regularization, finding that the optimal weight decay is 30x larger than standard practice. Since our regularized recipe monotonically decreases loss following a simple power law in parameter count, we estimate its best possible performance via the asymptote of its scaling law rather than the performance at a fixed compute budget. We then identify that ensembling independently trained models achieves a significantly lower loss asymptote than the regularized recipe. Our best intervention combining epoching, regularization, parameter scaling, and ensemble scaling achieves an asymptote at 200M tokens using 5.17x less data than our baseline, and our data scaling laws predict that this improvement persists at higher token budgets. We find that our data efficiency gains can be realized at much smaller parameter counts as we can distill an ensemble into a student model that is 8x smaller and retains 83% of the ensembling benefit. Finally, our interventions designed for validation loss generalize to downstream benchmarks, achieving a 9% improvement for pre-training evals and a 17.5x data efficiency improvement over continued pre-training on math mid-training data. Our results show that simple algorithmic improvements can enable significantly more data-efficient pre-training in a compute-rich future.
Multi-Task ICL September 2023
Learning shared safety constraints from multi-task demos.
Regardless of the particular task we want them to perform in an environment, there are often shared safety constraints we want our agents to respect. Manually specifying such a constraint can be both time-consuming and error-prone. We show how to learn constraints from expert demonstrations of safe task completion by extending inverse reinforcement learning (IRL) techniques to the space of constraints. Intuitively, we learn constraints that forbid highly rewarding behavior that the expert could have taken but chose not to.
Unfortunately, the constraint learning problem is rather ill-posed and typically leads to overly conservative constraints that forbid all behavior that the expert did not take. We counter this by leveraging diverse demonstrations that naturally occur in multi-task settings to learn a tighter set of constraints. We validate our method with simulation experiments on high-dimensional continuous control tasks.
